Scaling Databases: The Modulo Hashing Problem Visualized
Problem
The current database cannot handle the volume of incoming write requests. During peak times, there are too many write/update requests incoming per second, so requests are taking longer to execute. You can buffer requests, but if the database cannot fulfill them faster than they arrive, it will overflow. Let’s say you work in a bank and cannot afford to drop any requests.
Solution
To scale writes, you can either use a bigger database (scale vertically) or use multiple databases (scale horizontally). Let’s say you want to scale horizontally. So you add an extra database. Now, you need to figure out how to forward requests to multiple DBs.
You can do it in a round-robin style. The issue is that requests for user X are persisted across different DBs, which makes querying all records for X slower (we need to query all DBs to get results) and makes enforcing table constraints more difficult (cross-database referential integrity is handled outside the database engine). Since round-robin is not working for us because we lose referential integrity this way, we need to route requests so that user X always goes to Database 1, so that all of user X’s data is located on Database 1, and the database engine can perform referential-integrity checks for that user.
One way to achieve this is to use the modulo operator. We can take the modulo of user_id and use the result to determine which database to map our user to. Here’s an example of how it can be done. We can take our ID, convert it to an integer, and perform a modulo operation on it.
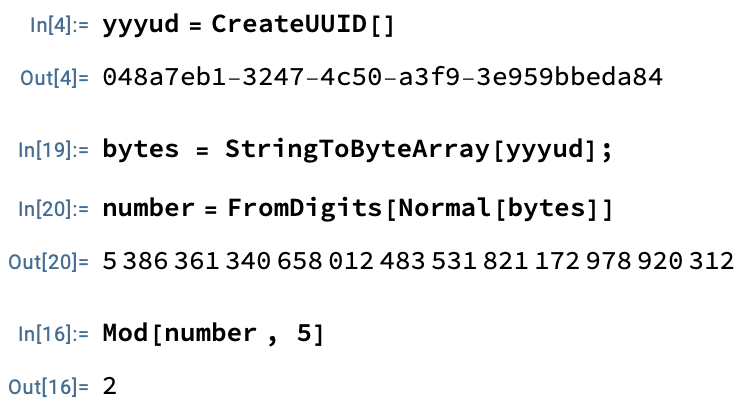
It works nicely as long as your ids are evenly distributed. If our ids are evenly distributed, then each database receives the same number of users. Let’s check if our UUIDs are evenly distributed.
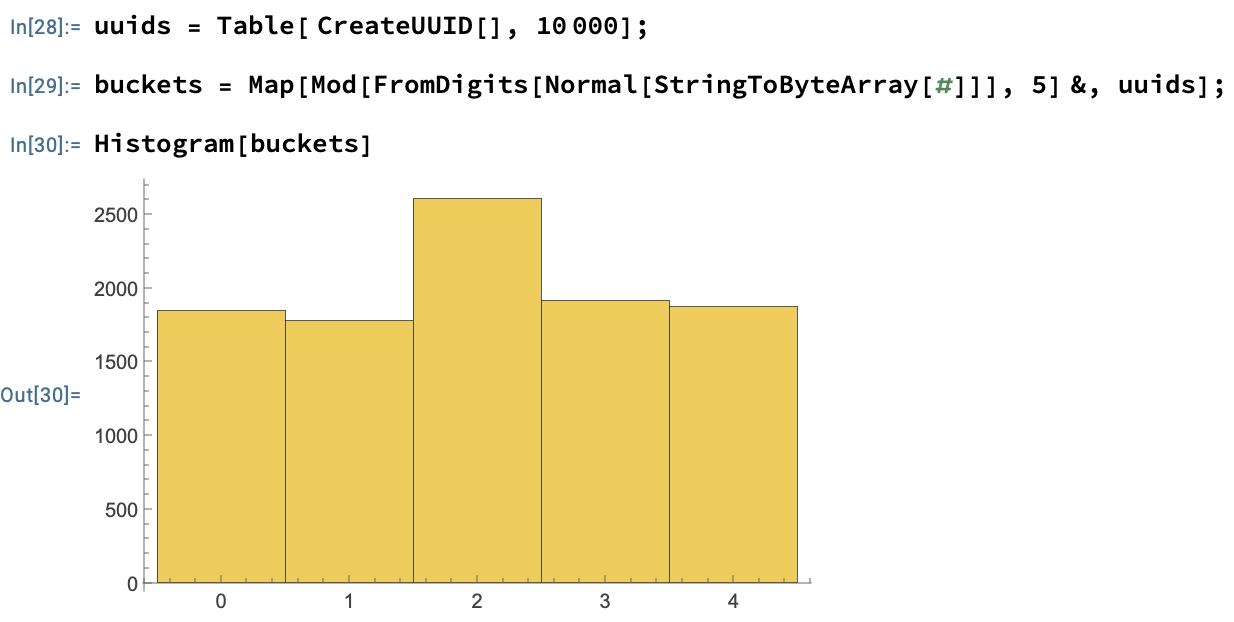
Pretty much evenly distributed, there seems to be some noise around the 2nd bucket, but it will smooth out as numbers increase.
Now what’s the problem with modulo hashing?
Problems with this approach start when we want to re-scale our database. Because when we rescale our database, instead of doing modulo 5 we do modulo 6 and records that were mapped to Database 1 are now going to be mapped to Database 6 and it will need to happen for many records.
5 % 5 -> 0
6 % 5 -> 1
7 % 5 -> 2
5 % 6 -> 1
6 % 6 -> 0
7 % 6 -> 1
Conclusion
Modulo hashing is simple and works well for static systems, but it becomes problematic when you need to scale. For some cases the number of records that need moving can go up as high as 93%. There are different ways of solving it. One way is to use consistent-hashing or lookup table.